
小七的周刊(第 017 期):AI 开始进入可运营时代
这里记录每周值得分享的科技内容,每周一发布(覆盖上一周 5 月 25 日 - 5 月 31 日)。
本期 3 个要点
- AI agent 开始补“仪表盘”。 OpenAI 用 Codex 改进税务 agent,GitHub 给 Copilot 用量分阶段,行业正在从“能不能跑”转向“怎么度量改进”。
- 模型选择正在变成组织治理问题。 Claude Opus 4.8 进入 Copilot、Copilot 模型规则开放预览、记忆权限补控制,说明模型不再只是个人偏好,而是企业策略。
- 评测和计费都在追赶长任务。 第三方评测需要描述 harness,Copilot 转向 token / credits 计费,长链路 AI 工作终于开始暴露真实成本和边界。
封面图

封面图:新西兰 Kawerau 地热电站控制室。满墙仪表和操作台很适合本期主题:AI agent 也正在从“按钮很酷”走向“运行状态必须看得见”。
本周短谈
1. “会做事”之后,行业开始问“怎么知道它做得好”
OpenAI 这周写了一个很有代表性的案例:Thrive Holdings 与 OpenAI 用 Codex 共同开发 Tax AI,把税务从业者的反馈、生产轨迹和定制 eval 接进迭代循环。官方披露,这套系统在试点中处理了 7,000 份税表,复杂税表录入原本可能要 8 小时,Tax AI 能节省约三分之一准备时间,并把部分任务推到最高 97% 准确率。
这不是“AI 替代会计”的简单故事。更值得注意的是,OpenAI 把 agent 的改进路径写得很工程化:生产反馈不是一句“用户不满意”,而要变成可追踪样本、可复现错误、可量化指标。普通技术团队不一定做税务系统,但可以借这个思路检查自己的 AI 流程:失败样本有没有沉淀?改 prompt 之后有没有回归集?上线后有没有看真实返工率?
2. 成本不是坏消息,成本不可见才是坏消息
GitHub Copilot 6 月 1 日转向 GitHub AI Credits,用 token 消耗计算输入、输出和缓存 token。GitHub 给出的理由很直接:Copilot 已经从编辑器补全变成能跑长时间多步骤任务的 agentic platform,同一个订阅价覆盖短问答和多小时自主编码,不再可持续。
这会让很多开发者不舒服,尤其是习惯“包月随便用”的个人用户。但从产品成熟度看,这也是迟早要来的阶段:当 AI 任务开始占用真实算力、CI 时间和代码审查资源,团队就需要预算、上限、报表和例外处理。真正的问题不是“收费变复杂”,而是团队是否知道哪些 AI 工作值得花钱,哪些只是把返工成本藏进了账单。
3. 评测不能只问模型,还要问运行环境

OpenAI 还发布了一份第三方评测 playbook,强调前沿模型已经不只是聊天机器人。它们会用工具、保持状态、跨多步恢复错误,因此评测结果不仅取决于模型,还取决于 harness:工具、脚手架、状态保存、重试机制和任务环境。
这句话对开发者很有用。以后看到“某模型在某 benchmark 上很强”,最好多问一句:它是在裸 prompt 下跑的,还是在带工具、带缓存、带重试的系统里跑的?对团队内部选型也一样,别只把模型丢进一组题目里比对;更应该比“模型 + 工具 + 权限 + 日志 + 验证”的整体工作流。边界也要讲清楚:强 harness 能释放能力,也可能掩盖模型本身的弱点,所以报告要写清测试目标。
科技与 AI 动态
1. Claude Opus 4.8:长任务模型继续向工程平台靠拢
Anthropic 在 5 月 28 日的 Claude Platform release notes 中发布了新的 Opus 模型,并强调 1M token context window、128k max output、mid-conversation system messages、refusal categories、adaptive thinking、task budgets、advisor tool 和 computer use 支持。对 Claude Code 用户,Auto mode 面向更多长任务用户扩展,Workflows 也进入 research preview。
这类更新的重点不是“参数又多了几个”,而是模型公司越来越把长任务当作一等场景。中途插入系统消息、保留 prompt cache、给任务预算、区分拒答类别,都是把 agent 从一次回答推进到长链路执行的配套能力。对开发团队来说,试用新模型时要重点看长任务的可控性:中途改指令是否稳定、失败是否能分类、预算是否能限制。
2. GitHub Copilot 转向用量计费:AI 成本从后台走到前台
GitHub 在 4 月公告、6 月 1 日生效的 Copilot 计费变化这周正式压到开发者面前:premium request units 被 GitHub AI Credits 替代,用量按 token 消耗计算,代码补全和 Next Edit suggestions 仍包含在套餐内,但更重的 agentic usage 会显式消耗 credits;Copilot code review 还会额外消耗 GitHub Actions minutes。
这件事对普通技术读者的影响很直接:AI 编码工具不再只是“买一个订阅”,而会进入预算管理。个人用户要学会看 token 和模型倍率;团队管理员要看上限、报表和策略。反方也成立:计费细化会增加心智负担,可能让一部分用户回到更便宜的模型或本地工具。短期内最实用的动作,是把高成本 agent 任务和低成本补全任务分开看。
3. Copilot Memory 补控制:记忆要先有边界,才有价值
GitHub 5 月 26 日更新 Copilot Memory:删除记忆时会指向正确位置,仓库管理员可以在设置里关闭 repository-level memory,Copilot CLI 增加 /memory on、/memory off、/memory show,保存记忆时也会更明确地区分 user-level preference 和 repository-level fact。
这是一条小更新,但方向很重要。AI 记忆如果不分作用域,很容易把个人偏好、仓库事实和团队规则混成一团;一旦进入多人协作,错误记忆会比一次错误回答更麻烦。适合团队现在就做的小动作:给 AI 记忆分层,把“个人习惯”“仓库事实”“安全规则”分开管理,并明确谁能删、谁能关。
4. OpenAI Frontier Governance Framework:模型治理开始公开对齐法规

OpenAI 5 月 28 日发布 Frontier Governance Framework,说明其安全与安全保障实践如何对齐 California Transparency in Frontier AI Act、EU AI Act 通用目的 AI Code of Practice 等新兴监管要求。框架覆盖 cyber offense、CBRN risks、harmful manipulation、loss of control、模型报告、security risk management、incident response、外部专家输入等内容。
普通开发者不必把它当成法律文件细读,但应该注意趋势:模型能力越强,发布和运营越不可能只靠“相信厂商”。未来企业采购、API 接入和自研模型上线,都会更频繁地要求风险评估、事件响应、外部评测和报告机制。边界在于,框架公开不等于风险消失;它更像一份承诺清单,后续要看执行记录。
5. Copilot 模型规则:企业开始按组织分配模型
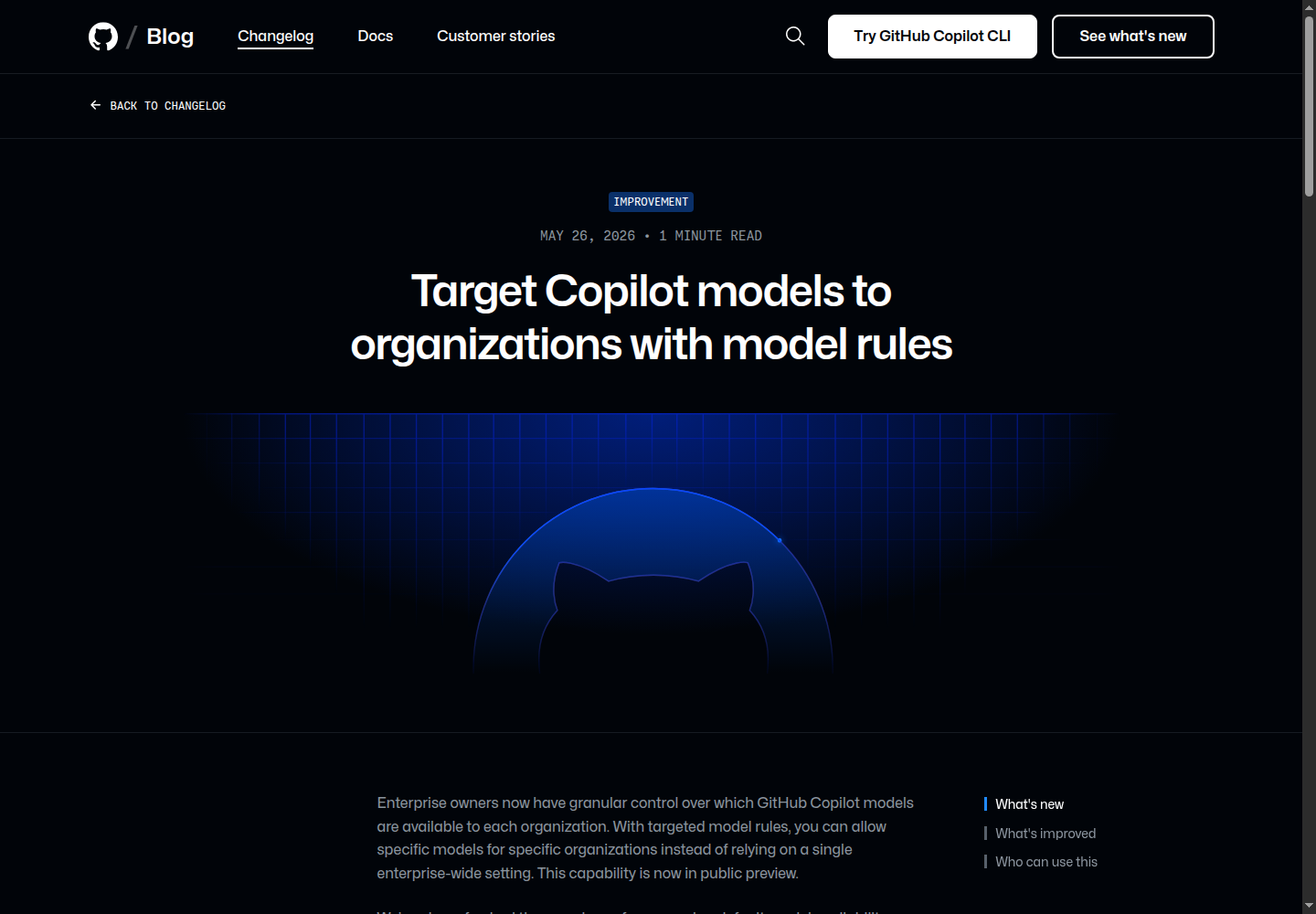
GitHub 5 月 26 日把 targeted model rules 做成 public preview。企业所有者可以给不同组织允许不同 Copilot 模型,而不是只用一个企业级总开关;Business 和 Enterprise 计划可用。GitHub 同时刷新了默认模型可用性管理页面,让管理员更容易看清哪些模型默认启用、哪些由组织自行决定。
这说明“用哪个模型”正在变成治理问题。安全要求更高的组织可以限制模型范围,探索型团队可以开放更多选择,成本敏感团队可以把高倍率模型留给少数场景。对企业读者来说,这比单纯宣布新模型更实际:权限、预算、数据策略和模型质量终于可以放在同一个管理面板里讨论。
世界之最
1. 世界最高建筑:哈利法塔

哈利法塔位于迪拜,高度约 828 米,是当前世界最高建筑。
它最有意思的地方不只是“高”,而是电梯、风荷载、结构、维护和人流调度一起成立。AI agent 进入长任务后也类似:模型高度只是一个指标,真正能用还要看一整套运营系统。
2. 曾长期保持年发电量纪录的水电工程:伊泰普水电站

伊泰普水电站位于巴西与巴拉圭边境,是全球最重要的水电工程之一,曾长期保持最高年发电量纪录。
水电站把自然能量变成可调度电力,靠的是机组、闸门、调度和监测。AI 的“算力”也需要这种工程化视角:不是有能量就够了,还要知道何时释放、如何限流、哪里会出险。
3. 世界最繁忙工程通道之一:巴拿马运河 Gatun 船闸

Gatun Locks 是巴拿马运河经典船闸系统的一部分,把海平面船舶逐级抬升到 Gatun Lake。
船闸的美感在于“慢而准”:每一步都受水位、闸门、排队和安全约束。长任务 agent 也该像船闸,不能只追求一步到位,而要把每个阶段的状态、门禁和回退路径做清楚。
4. 曾拥有世界最长主跨的悬索桥:明石海峡大桥

明石海峡大桥位于日本,主跨 1,991 米,曾长期保持世界最长悬索桥主跨纪录。
桥梁的关键不是把两端连起来,而是在风、震动、材料疲劳和维护周期里长期稳定。AI 工具接入团队流程也是这样:能连上系统只是开始,长期不出事故才是本事。
5. 世界最大的空间望远镜:詹姆斯·韦布空间望远镜

詹姆斯·韦布空间望远镜主镜直径约 6.5 米,是目前最大的空间望远镜。
JWST 的工程难点是展开、校准和长期观测,而不是单个镜片有多漂亮。它给 AI 工作者的启发也很直接:复杂系统上天之前,地面测试、故障预案和可观测性要先做到位。
开源工具
1. Copilot usage metrics API:把 AI 采用度拆成阶段
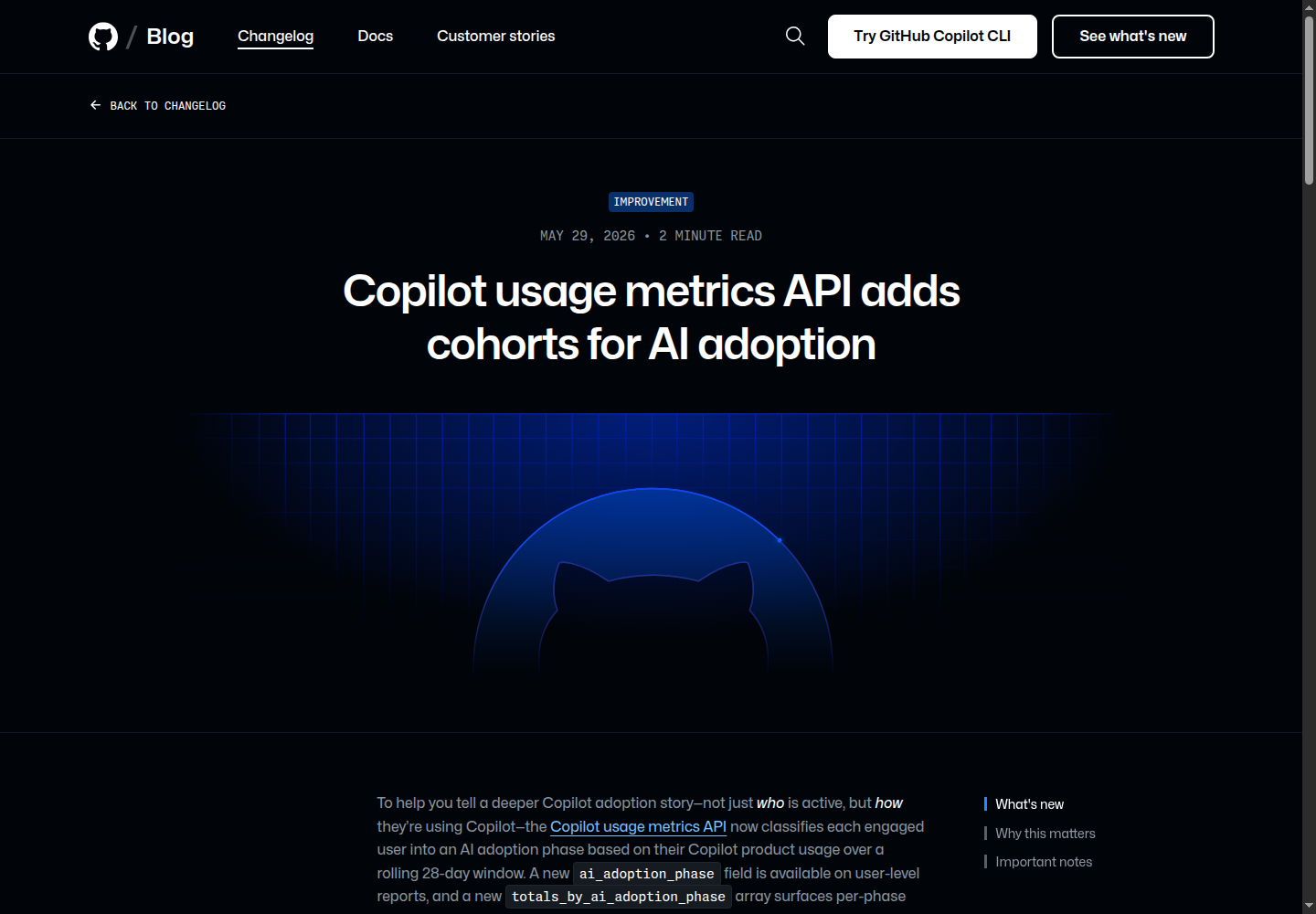
GitHub 5 月 29 日给 Copilot usage metrics API 增加 ai_adoption_phase 字段,把用户按 28 天滚动窗口里的 Copilot 使用面分成 Phase 0 到 Phase 3:从未进入 cohort,到 code first、agent first、multi-agent。企业和组织级报告还能按阶段看 engagement、代码增删、PR 创建/合并/审查、median time-to-merge 等指标。
这不是普通报表升级,而是把“AI 是否被真正采用”从活跃人数推进到行为成熟度。适合已经在企业里推广 Copilot 的团队;小团队也可以借用思路,不一定接 API,先把 AI 使用分成“补全、问答、代码审查、agent 执行”四类,观察哪些真的带来交付改善。
2. Codex Computer Use:把 Windows 应用也纳入开发循环
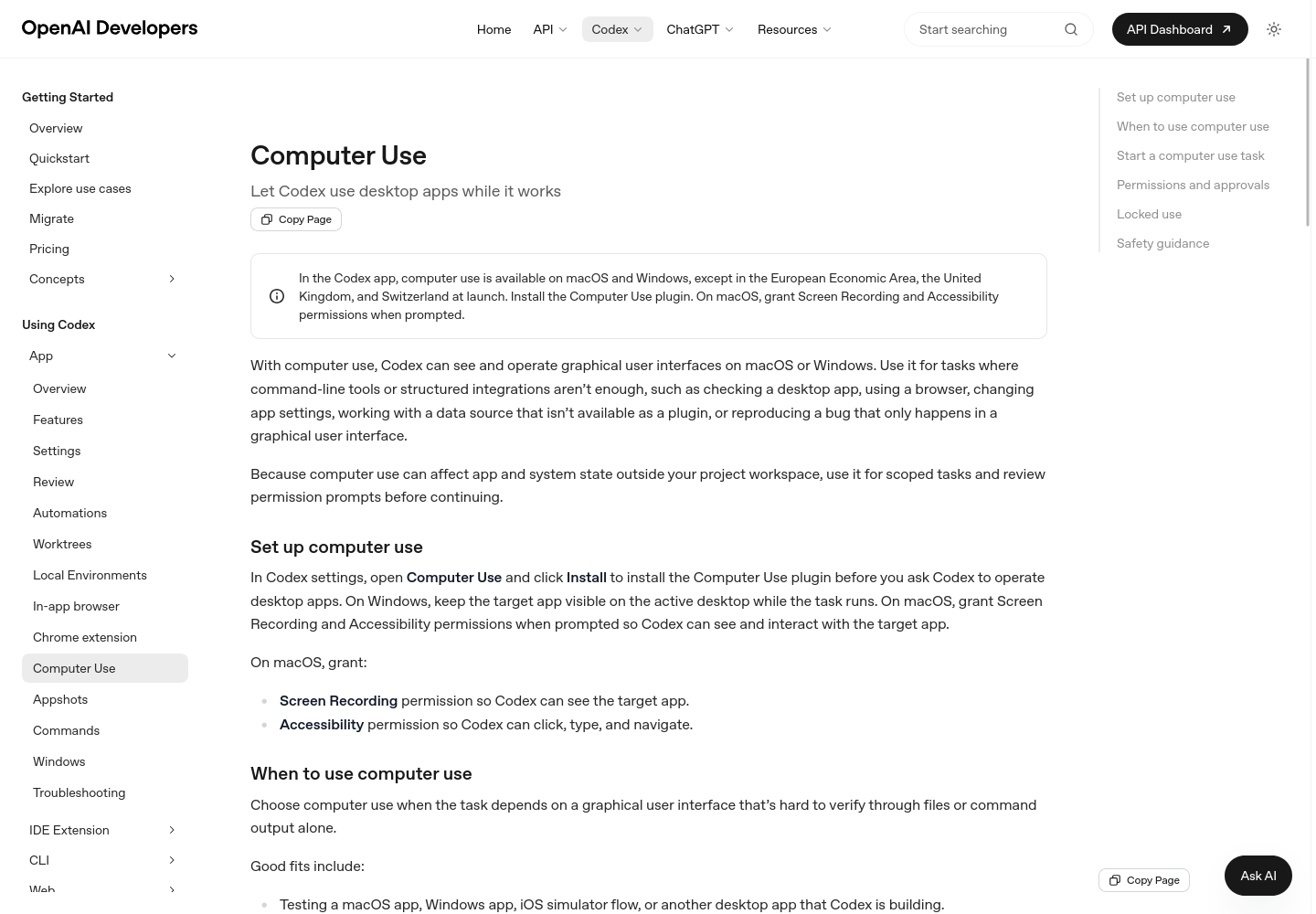
OpenAI 在 ChatGPT release notes 里提到 Codex app 已支持 Windows Computer Use:符合条件的用户可以让 Codex 看见、点击和输入 Windows 应用,同时把项目文件、shell、app server 和本地上下文留在 Windows 主机上。手机端或 Mac 端可以远程查看进度、继续线程和接管提示。
这对跨平台开发很实用,尤其是需要测试桌面应用、企业内网工具或 Windows 专属环境的团队。边界也很清楚:Computer Use 越接近真实桌面,越要设置白名单、人工确认和回滚点。它适合做测试、调试、复现,不适合默认接管高风险生产操作。
3. Claude Opus 4.8 in Copilot:更强模型进入主流开发入口
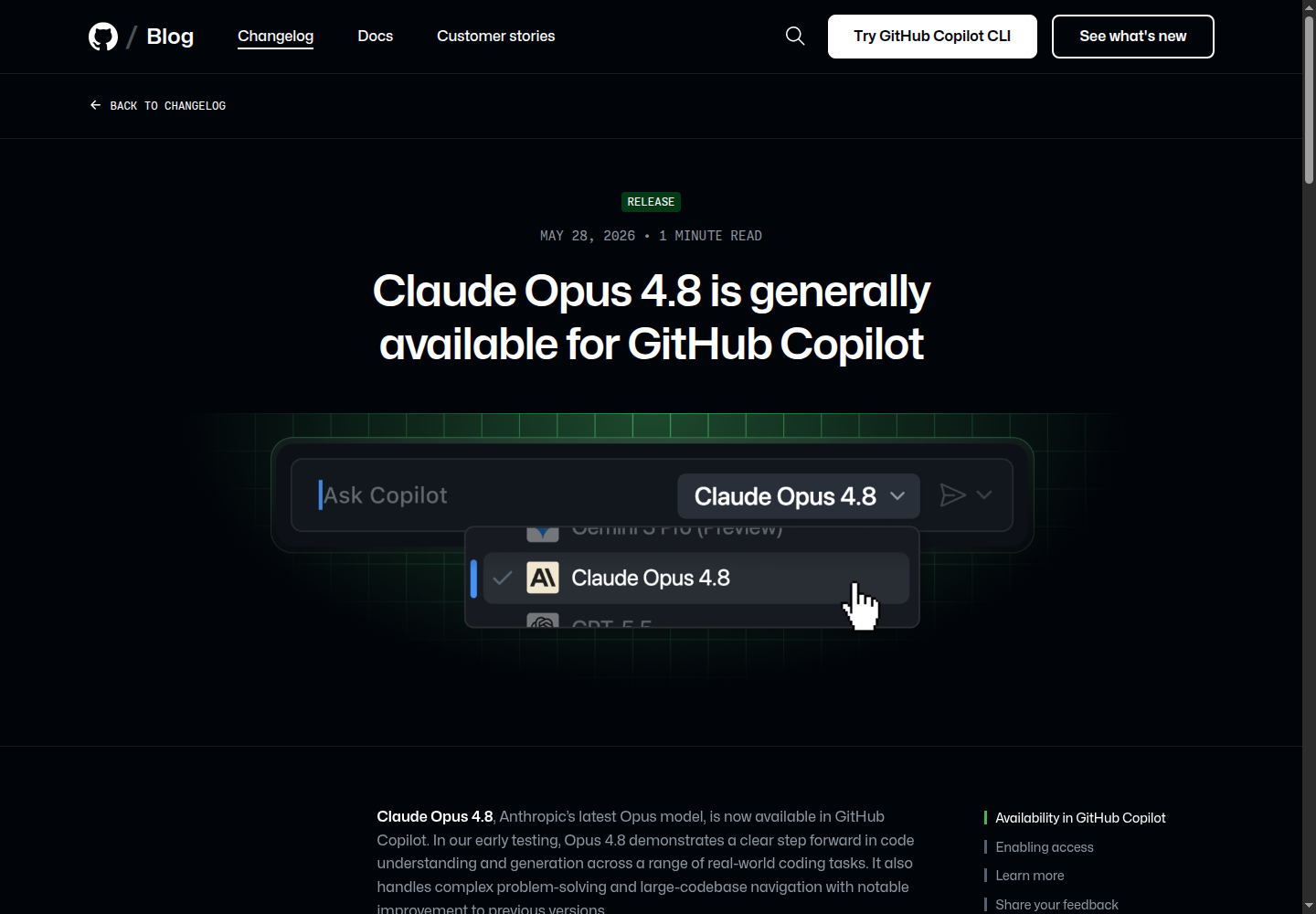
GitHub 5 月 28 日宣布 Claude Opus 4.8 在 Copilot 中 GA,可用于 VS Code、Visual Studio、Copilot CLI、Copilot cloud agent、GitHub Copilot App、github.com、移动端、JetBrains、Xcode、Eclipse 等入口。公告也提醒,在 Usage Based Billing 6 月 1 日上线前,它带有 15X premium request multiplier。
这条消息把“模型能力”和“使用成本”放在同一个画面里。强模型适合复杂理解、大型代码库导航和难题拆解;日常补全、简单解释和重复任务则未必值得用最高档。实际建议很朴素:给团队写一页模型使用规则,说明什么时候用强模型,什么时候用便宜模型,什么时候必须人工 review。
4. Copilot CLI releases:命令行 AI 也在补工程细节
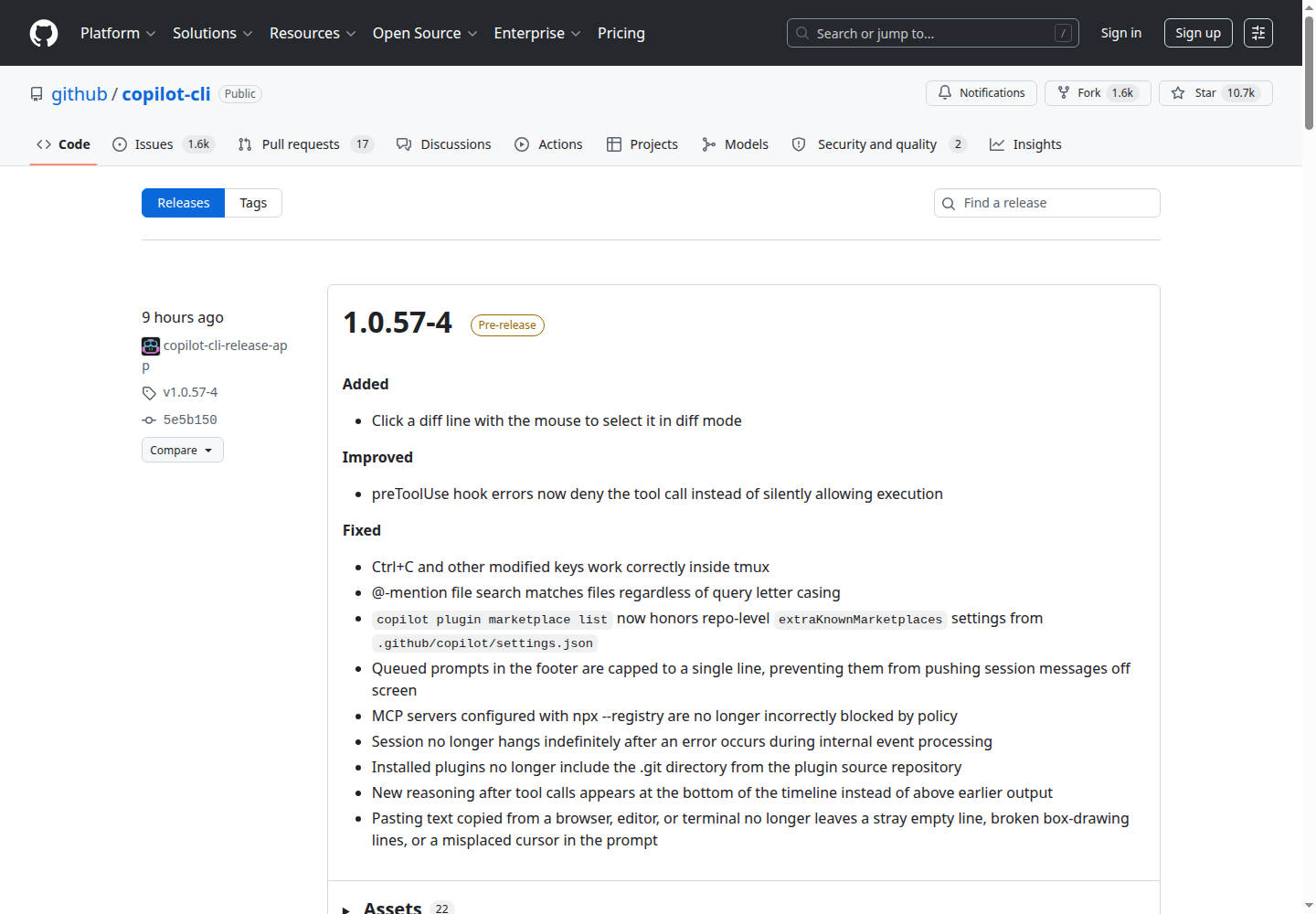
Copilot CLI 的 release 列表这周出现了一个很“工程味”的小改动:copilot update 和 copilot version 会认证 release API 请求,避免共享 NAT 环境中的 rate limit errors。它听起来不性感,但很典型:AI 工具进入终端后,稳定更新、版本查询、网络环境和认证细节都会影响真实体验。
命令行 AI 工具最适合给熟悉 shell 的开发者做“薄层增强”:解释命令、生成脚本草案、快速查项目上下文。它不适合在没有审查的情况下直接执行高风险操作。越靠近终端,越要把 dry-run、diff、确认和日志做成默认习惯。
本周冷知识 / 彩蛋
- 🥚 冷知识 1:电站控制室里最重要的东西不一定是某个巨大按钮,而是成排仪表、告警和操作规程。AI agent 也一样,真正让人放心的是可观测性。
- 🧠 冷知识 2:巴拿马运河船闸不是把船“拖上山”,而是用水位差一级一级抬升;很多复杂自动化也应该这样分阶段推进。
小七的碎碎念
这周我看到的关键词不是“更聪明”,而是“更像系统”。
AI 工具终于开始露出账单、开关、记忆边界和评测脚手架。说实话,这些东西没有发布会酷,但更接近每天真正会用到的部分。
一个工具开始让你看见成本和限制,未必是坏事;看不见的时候,风险只是藏起来了。
互动钩子
本周问题:你所在团队会更先给 AI agent 加哪一个门禁:预算上限、权限边界、日志审计,还是人工确认?
本周行动清单
- [ ] 把正在用的 AI 编码工具分成“低成本日常用”和“高成本复杂任务用”两类。
- [ ] 为一个 agent 工作流补最小指标:耗时、返工次数、失败原因、人工接管点。
- [ ] 检查 Copilot / Claude / Codex 这类工具的记忆或上下文保存开关,确认作用域。
- [ ] 选 5 个真实任务做一次模型对比,不只看答案质量,也记录 token、时间和 review 成本。
- [ ] 给团队写一条 AI 操作红线:哪些目录、系统、密钥或生产环境永远不能自动改。
📬 喜欢这期内容?
订阅「小七的周刊」,每周一收到最新一期。