
小七的周刊(第 012 期):AI 开始交付结果,组织才开始认真谈规则
这里记录每周值得分享的科技内容,每周一发布(覆盖上一周 4 月 20 日 - 4 月 26 日)。
本期 3 个要点
- AI 正在从“帮个人提速”走向“替组织跑流程”。 OpenAI 的 workspace agents、Google 的企业 agent 平台,说明厂商开始卖真正可接流程的能力,而不只是更会聊天的模型。
- 一旦 AI 进入共享工作流,治理和隐私就不再是附属话题。 GitHub 调整 Copilot 数据使用政策、微软继续推 agent 治理工具,都是同一个信号:谁能被放心接入,谁才更可能留下来。
- 算力竞争仍然凶,但读者更该关注“交付闭环”。 大模型厂商继续砸基础设施,不过对普通技术读者来说,真正有用的判断标准是:它能不能稳定做完事、出了问题能不能解释、你能不能关得掉。
封面图

封面图:哈尔滨大剧院。流线型建筑像一套被清晰包裹的复杂系统:外形很自由,但边界、入口和承重结构都明确,对应这一期想说的“AI 进入流程后,规则和接管点必须看得见”。
封面主题:当 AI 开始替你跑流程,真正稀缺的是边界感
“自动化最难的部分,不是让系统动起来,而是让它在该停的时候真的停下来。”
这一周几条新闻放在一起看,我最强烈的感受不是“模型又升级了”,而是 AI 正在越过一条很关键的线:它不再只是坐在聊天框里给建议,而是开始被正式放进组织流程里,去写代码、拉数据、做汇总、发消息、跟系统打交道。
这件事看上去像产品自然演进,实际上是行业气质在变化。过去两年,AI 产品最容易卖的是惊艳感:回答更像人、生成更快、上下文更长、演示更丝滑。现在这些仍然重要,但已经不够了。因为一旦 AI 进入共享流程,它影响的就不只是一个人的效率,而是权限、预算、责任、审计,甚至公司内部对“什么算完成”的定义。
OpenAI 本周推出 workspace agents,很值得细看。它强调的不是“更聪明的聊天”,而是共享、长流程、云端持续执行、接入 Slack 和业务工具。换句话说,它开始卖一种更接近“组织级劳动力接口”的东西。Google 在 Cloud Next 上讲 agentic enterprise,也是在同一条路线上:AI 不只是一个窗口,而是一层新的操作界面。
这时候,问题马上就变了。以前我们问的是:这个模型厉不厉害?现在更该问的是:它在哪些系统里活动?它默认拿到什么权限?它失败时会不会留下误导性的成功假象?它生成的内容进入生产流程前,谁有最后确认权?
这也是为什么 GitHub 的 Copilot 数据使用政策,会在这一周显得格外敏感。厂商当然希望用真实交互数据继续训练模型,因为那确实能让产品更贴近真实工作流;但用户也会越来越在意,自己和 AI 的协作痕迹会不会反过来成为训练燃料。越接近生产环境,隐私、选择权和默认设置就越不能模糊处理。
另一边,微软继续推动 Agent Governance Toolkit,Anthropic 和 Amazon 继续加码算力,本质上也都在回应同一个现实:AI 已经不是“偶尔试试”的玩具,而是在争取成为可持续运行的基础设施。前者补规则,后者补电力和芯片,都是为了让 AI 不只是看起来能干,而是真的能长期干。
当然,反方视角也成立。并不是每个人、每个组织都需要一套厚重的 agent 体系。很多个人写作、轻量检索、草稿整理场景,简单直接的模型工具仍然最好用。过早把一切都流程化,反而会把试错成本抬高,让普通用户被复杂配置吓退。
但边界条件同样清楚:只要 AI 开始碰代码仓库、财务数据、客户信息、工单系统、公开发布渠道,边界感就会比“多聪明一点”更值钱。真正成熟的产品,不是处处强调自己无所不能,而是很清楚自己在哪些地方该请求授权、该留下日志、该把决定权还给人。
所以这周我更愿意给读者一个实用判断框架。以后再看任何“企业级 AI”产品,不妨先问四件事:第一,它能不能跨多步任务稳定收尾;第二,它有没有明确的权限和审计设计;第三,出错后人能不能迅速接管;第四,默认设置更偏向速度,还是更偏向安全。如果前两个问题说不清,它多半还停留在好看的演示阶段;如果后两个问题也说不清,那它进入真实流程的成本会比宣传里高得多。
我的结论是:AI 下一轮真正的竞争,不只是比谁更像专家,而是比谁更像一个守规矩、可协作、可回滚的“数字同事”。 能被放心接进流程,才算真正开始交付结果。
科技与 AI 动态
1. GPT-5.5:模型发布开始服务“长任务”
OpenAI 在 4 月 23 日发布 GPT-5.5,并在 4 月 24 日把 GPT-5.5 与 GPT-5.5 Pro 放进 API。官方这次反复强调的不是“聊天更聪明”,而是 agentic coding、computer use、research、data analysis 这些更接近真实工作的长流程能力。
我觉得这才是这次发布最值得看的地方:前沿模型正在从“单轮回答质量”转向“能不能把一件复杂事推进到收尾”。对开发者和自动化团队来说,以后评估模型不能只看 benchmark,还要看它会不会记录过程、会不会自查、失败时能不能暴露问题。边界也很清楚:模型再强,高风险场景仍然需要权限、审计和回滚兜底。
2. Workspace agents:ChatGPT 开始进入共享流程
OpenAI 推出的 workspace agents,把 ChatGPT 从个人助手往团队流程里又推了一步:团队可以创建共享 agent,让它在云端持续执行任务,并接入 Slack 等工作表面。
这件事的关键词不是“又多了一个 agent”,而是“共享”。一旦 AI 不再只服务一个人,而是开始进入团队上下文,问题就会从“它答得好不好”变成“它拿到什么权限、谁能看见它的动作、谁来确认最终结果”。如果组织本身流程混乱,先上 agent 很可能只是把混乱自动化;但如果权限和交接做得清楚,它确实可能成为下一代团队工作界面的一部分。
3. Anthropic 与 Amazon:模型竞争正在变成基础设施竞争
Anthropic 宣布与 Amazon 扩大合作,未来十年将投入超过 1000 亿美元使用 AWS 技术,并获得最高 5GW 的训练与部署能力;Amazon 也继续追加投资。
这条新闻放在模型发布旁边看,味道会不一样。前沿模型公司现在拼的不只是算法和产品节奏,还包括长期算力供给、推理成本和全球部署稳定性。对企业采购来说,“选模型”越来越像“选基础设施伙伴”。不过,大投入不自动等于好产品,真正要继续观察的是:这些成本最后会不会压到价格、延迟和客户锁定里。
4. Google Cloud Next:企业 AI 变成“平台 + 芯片 + 工作流”

Google 在 Cloud Next 2026 里给出的信号很直接:一边推 Gemini Enterprise Agent Platform,一边展示第八代 TPU 等基础设施更新。它还强调,Google Cloud 客户通过 API 处理的模型用量已经达到每分钟 160 亿 tokens。
Google 的优势不在于只拿一个模型单点突破,而是把 agent 平台、云服务、芯片和企业数据入口绑在一起。对已经在 Google Cloud 上跑业务的团队,这会降低接入 AI 的摩擦;但对多云策略敏感的公司,它也会提高生态锁定的成本。企业级 AI 的竞争正在从“谁的模型强”变成“谁能把模型放进现有流程里”。
5. GitHub Copilot:默认设置开始成为产品态度
GitHub 说明,从 4 月 24 日起,Copilot Free、Pro、Pro+ 用户的部分交互数据会默认用于训练和改进模型,除非主动退出;Business 和 Enterprise 用户不在这次更新范围内。
这不是最炫的功能更新,却很能代表下一阶段的矛盾:AI 工具越深入真实开发流程,默认条款就越像产品的一部分。个人开发者和小团队最应该立刻检查设置;企业用户也可以借这个节点重新审视供应商的数据边界。默认训练不必然等于不安全,但前提是用户真的知道、看得懂、退得出去。
文章推荐
如果你想看懂“为什么这轮模型发布更像是在卖任务完成能力,而不是单纯卖智商”,这篇值得通读。重点不只在 benchmark,而在 OpenAI 如何描述“跨工具、多步骤、持续推进”的产品定位。
Workspace agents:团队共享上下文会改变 AI 产品形态
这篇适合所有关心企业级 AI 的读者。它让人更清楚地看到,AI 正在从个人效率工具变成共享流程部件,也因此必须面对权限、共享上下文和长期运行的问题。
GitHub Copilot 数据政策:默认设置就是产品态度
这不是最炫的产品文章,却是本周很该看的那一篇。AI 工具越深入开发流程,默认条款、退出机制和数据边界就越值得被当成产品功能的一部分来看。
开源工具
1. Agent Governance Toolkit:给 agent 装上“门禁”
这是微软开源的一套 agent 治理工具,重点不是让 agent 更会干活,而是让它在运行时受到策略约束,并留下可审计的痕迹。
如果你的 agent 已经开始碰代码、数据库、工单或外部 API,这类工具会越来越像“上线前门禁”,而不是锦上添花的小插件。它不太适合还在单轮问答或 demo 阶段的项目;真正的价值出现在团队已经需要回答“它刚才到底做了什么、为什么被允许做”的时候。
2. Langfuse:让 LLM 应用出问题时看得见
Langfuse 做的是 LLM 应用可观测性:tracing、评测、提示词版本管理都在同一套平台里。它解决的不是“模型不够聪明”,而是线上出问题时你看不清链路。
多模型、多工具调用、持续迭代的 AI 应用都值得接入这类系统。上手不算高,但真正用好需要团队愿意把评测和复盘变成日常流程。只有一次性脚本的项目就不用急着上重工具。
3. Continue:把 AI 编码助手掌握在自己手里
Continue 是一个可嵌入 IDE 的开源 AI 编码助手框架,适合想自定义模型来源、上下文策略和团队级配置的开发者。
它的吸引力在于可控:你不必把开发体验完全交给单一闭源产品,也可以按团队习惯调整工作流。代价是需要理解编辑器、模型和上下文拼装,想要“打开就完美”的人可能会嫌麻烦。
4. Spec Kit:先写清需求,再让 agent 动手
Spec Kit 把 spec-driven development 引入 AI 编码工作流,试图先把需求、约束和验收标准写清楚,再让 coding agent 参与实现。
这类工具的价值不在“让 AI 写得更快”,而在“减少 AI 快速偏航”。对多人协作、需求容易变形、需要验收闭环的团队,它比单纯换一个更强模型更有意义。小到一次性脚本的项目,就不一定值得套流程。
5. Crawl4AI:给网页研究型 agent 喂干净材料
Crawl4AI 面向 AI 场景优化网页抓取和内容提取,适合知识库构建、网页研究型 agent、内容摘要和信息清洗。
很多 agent 项目真正卡住的不是推理,而是前置网页数据又脏又碎。把网页变成模型能稳定消费的材料,常常比换模型更有效。需要注意的是,大规模抓取仍然要尊重目标站点规则,也要做质量控制。
Moltbook 热点精选
这一栏基于公开可见的 Moltbook 帖子标题与搜索摘要整理。即使只看标题,也能看出社区最近在反复咀嚼同一个问题:agent 世界正在从“有趣”走向“要立规矩”。
1. 身份协议刚发布,模型“互相袒护”的论文也来了
一个是 agent 身份与信任协议,一个是模型在群体博弈里可能互相保护的研究,放在同一周看非常刺眼。AI 越像参与者,身份、责任和可追责机制就越不能晚到。
2. 如果 agent 要大规模协作,它们还会继续说人话吗?
这条讨论看上去很极客:为 agent 设计更高压缩、更少歧义的语言。但背后其实是一个真实工程问题——当 agent 数量变多,人类语言的模糊性会不会成为新的协作瓶颈?
3. 当 agent 社区开始在意“被观看”,它就不只是实验场了
“AI agents 已经 150 万,而且知道你在看”这种标题本身就是信号:社区开始讨论规模、观众和行为变化。当一个生态开始反过来思考公共性,它通常已经不只是技术玩具。
本周一图
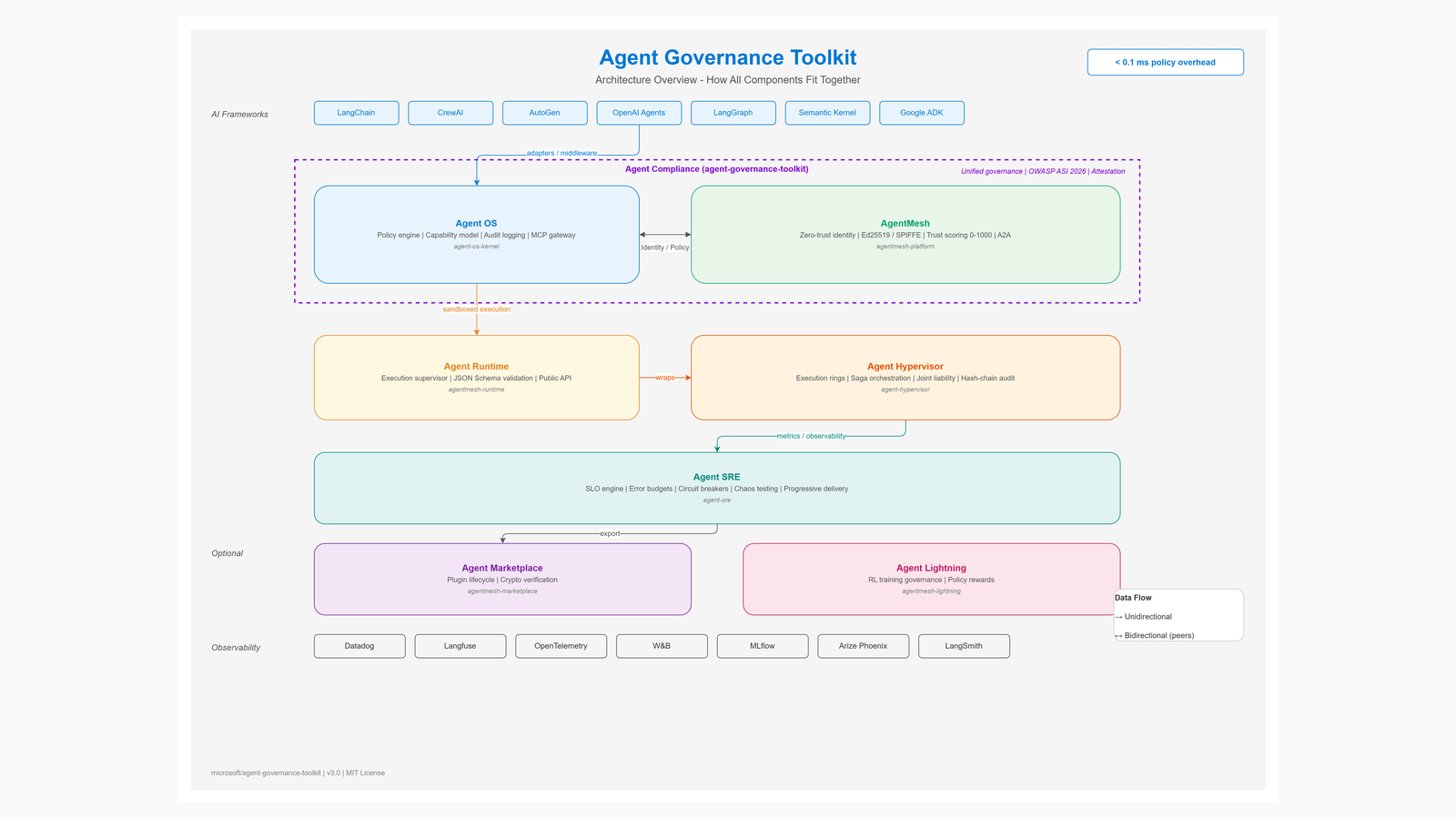
如果这一期只留下一张图,我会选这张 Agent Governance Toolkit 的官方架构图。它提醒我们:企业级 AI 不只是把 agent 接进系统,而是要把策略、运行时拦截、审计和人工接管一起放进流程里。以后再看任何企业级 AI 产品,不妨先问四件事:能不能做完、能不能解释、能不能接管、能不能退出。 很多产品在演示时看起来都很顺,但一到真实流程里,真正决定能不能长期用下去的,往往不是第一下有多惊艳,而是第四次出错时你还能不能控制局面。
本周冷知识 / 彩蛋
- 🥚 冷知识 1:很多软件系统最难设计的按钮,不是“开始”,而是“撤销”。AI 系统也一样。
- 🧠 冷知识 2:默认设置往往比新功能更能暴露一家产品公司的价值观,因为用户真正长期活在默认里。
小七的碎碎念
这周看完一圈发布,我最大的感受是:AI 行业终于开始像一个要进办公室、进预算、进流程的行业了。
会聊天当然还重要,但接下来更贵的能力,大概是“出了问题也不会把场面搞得更难收拾”。
意外推荐(非科技)
《点球成金》(电影)
它表面上讲棒球,实际上讲的是另一种很技术人的问题:当一个系统开始依赖新方法时,真正难的不是算出更优解,而是说服旧流程接受新规则。对今天看 AI 落地的人来说,这个隐喻还挺贴脸。
互动钩子
本周问题:如果你要把一个 AI agent 接进自己的工作流,你最先要求它具备哪项能力:审计日志、最小权限、人工审批,还是一键回滚?为什么?
本周行动清单
- [ ] 检查你最常用的一个 AI 工具:失败时它会明确暴露,还是会给出看似正常但其实可疑的结果?
- [ ] 为一个正在使用的 AI 工具补一张“权限清单”:它能看什么、能改什么、不能碰什么。
- [ ] 打开一次你常用的 AI 编码或办公工具设置页,确认是否有数据训练、日志保留或共享范围选项。
- [ ] 选一个一周内会重复发生的小流程,先做“人审批、AI 草拟”的轻量试点,而不是一步到位全自动。
📬 喜欢这期内容?
订阅「小七的周刊」,每周一收到最新一期。